5 Ad Monetization Tests That Didn’t Go as Planned

Whether you’re just starting out in ad monetization or you’re a seasoned professional who believes nothing can catch you off guard, the truth remains that every so often, even small tweaks to your setup can deliver unexpected results. Sometimes, a modest adjustment can lead to a surprising boost. Other times, those same changes can turn into a frustrating setback.
In this article, GameBiz Consulting gathered a few real-world test cases from the mediation and network side of ad monetization. While we’ve run many more, we selected these examples because they occurred repeatedly, across multiple apps, genres, ad formats, mediation platforms, networks, and regions, making them far from isolated incidents.
Let’s begin with one that challenges the very foundation of how we approach testing.
1. How Reliable Are Our Mediation Tests?
In 2023, we decided to put the testing process itself under scrutiny. In other words, to check how trustworthy the testing tools provided by mediation platforms really are. To do this, we ran what we called an “empty test,” where no changes at all were introduced. The setup looked like this:
- Group A (Control): No modifications applied
- Group B (Experimental): No modifications applied
The outcome at the time was, frankly, discouraging. The two groups differed by as much as 3.78%. That naturally raises the question: if an optimization shows a lift of less than 4%, can we honestly count that as a meaningful improvement and justify rolling it out across the board?
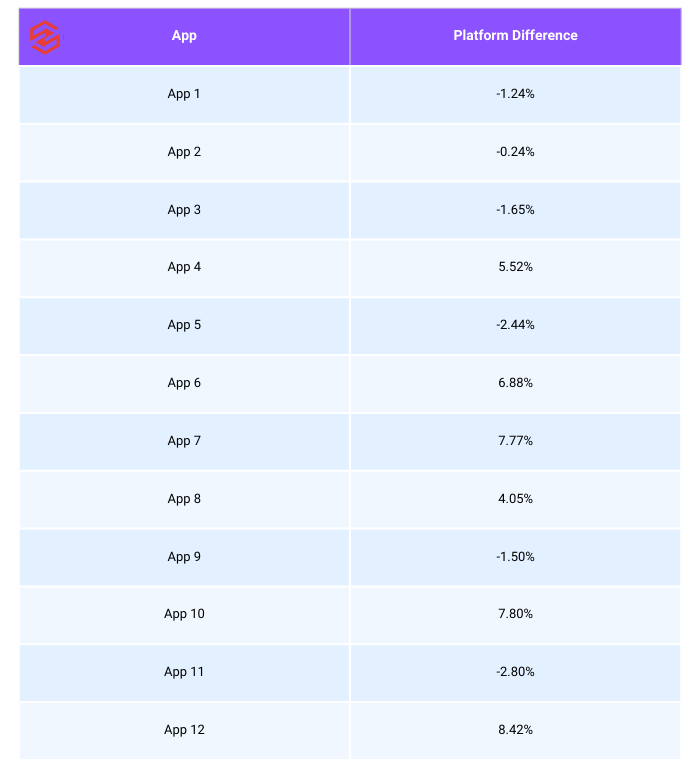
Fast forward more than two years, and we hoped things would have improved. To find out, we repeated a series of empty tests. This time, we used the two mediation platforms that, as of our May 2025 research, command roughly 80% of the market: MAX by Applovin and LevelPlay by Unity.
Unfortunately, our optimism didn’t last long. The results, gathered from a dozen different apps (ranked by scale below), told a very different story. If you feel like running the same experiment, we’d be curious to know: what did your results look like?
2. Can Banner Refresh Rate AB Tests Be Trusted?
This might be the trickiest case in our entire test portfolio. Banners, especially in hyper-casual titles, can still make up a solid chunk of revenue. Best practice says you should experiment with refresh rates, and over the past year, many publishers have shortened theirs, moving from 10 seconds to just 5. We ran those same experiments. Sometimes the results were encouraging, but other times they left us with nothing but a headache.
Here’s one striking example. The control group used a 10-second refresh, while the experimental group ran at 5 seconds. At first glance, the results were thrilling: a +38.9% ARPDAU increase. Naturally, we rolled out the 5-second setup to everyone.
Fairy-tale ending? Not quite. Once the change went live, the uplift was nowhere near as strong. Comparing pre-test to post-test performance, the real improvement was closer to +8%, a big gap from the near +39% the test had suggested. Looking deeper, we realized the control group’s performance had unexpectedly dropped, which inflated the reported gain by lowering the baseline.
We’ve encountered this more than once. Nowadays, when possible, we either run the test through Firebase instead of relying on mediation or simply compare performance before and after making the switch.
3. Can Adding a Bidder Actually Lower Your Ad ARPDAU?
According to the sales pitch, moving from waterfalls to bidding was meant to solve every problem an Ad Monetization Manager could have. No more manual tweaking, eCPMs and ad ARPDAU soaring, UA campaigns running more smoothly thanks to stronger LTVs, and who really needs control over their inventory anyway, right?
That, in short, has been the comforting narrative pushed by both ad networks and mediation platforms over the past several years.
To be fair, automation has reduced much of the repetitive manual work around ad serving. But it has also stripped publishers of nearly all control. Bidding was supposed to streamline processes and remove latency. The entire auction is built on two basic assumptions:
- It runs simultaneously for all networks, so whether you integrate 5 or 10, latency shouldn’t differ.
- The system is fair: the highest bid wins unless a technical failure prevents delivery, something that, in theory, should be rare if you’re working with a top-tier mediator.
With those principles in mind, it’s always puzzling when an AB test shows worse results after adding a new bidder. In theory, bidders shouldn’t increase latency; they should only win with the best price, and their presence should strengthen competition. So why does the test group sometimes show lower eCPMs than the control?
We’ve run into this repeatedly: situations where a newly added bidder takes a meaningful share of revenue and impressions (often more than 5%), yet the overall outcome is worse, with ad ARPDAU dropping compared to the control. A few examples are illustrated in the table at this link.
Whenever this happens, the common thread is clear: eCPM in the test group comes in lower than in the control, which drags ARPDAU down.
We’ve raised this with multiple mediation and network partners, but none of the explanations so far have really added up. If you’ve formed a theory of your own, we’d be more than interested to hear it.
4. Why Can a Weak Network Still Be Crucial for Competitiveness?
It’s no secret that Meta Audience Network’s performance took a steep hit after Apple deprecated IDFA. To put numbers on it: across the GameBiz publisher portfolio, Meta’s median share of wallet sits at 1.4%, the average is 2.6%, and the range goes from as low as 0.23% up to 6.9% (with higher shares typically showing up in less competitive markets).
When a network’s share of wallet falls below roughly 1%, we often consider AB testing its removal as it doesn’t seem to add much value. But with Meta, things haven’t been that straightforward. More than once, removing it has led to a surprisingly large drop in ad ARPDAU within the test group. It almost feels as though simply having Meta present in the auction boosts competitiveness among the other bidders.
And it’s not just Meta. We’ve observed similar effects with certain instances from other networks. While waterfall instances are mostly a relic of the past, they’re still around, particularly in banner waterfalls with AdMob or GAM, Applovin on LevelPlay, or in COPPA traffic through AdMob mediation.
If you decide to eliminate low-performing instances through testing, be prepared for unexpected results. A few cases from our archive illustrate the point:
Example 1: iOS app, interstitial waterfall in the U.S. Removing 5 out of 47 instances, together accounting for only 0.69% of share of wallet, resulted in a -10.7% drop in ad ARPDAU.
You can see the test results at this link.
Example 2: iOS app, banner waterfall in the U.S. Removing a single instance with a 1.6% share of wallet (out of 14 total) led to a -5.6% decrease in ARPDAU.

5. How Can a Nonexistent Waterfall Instance Still Serve Impressions?
Most of us have run into this at some point. Back in the days of heavy waterfall management, handling dozens, or even hundreds, of instances in a single day was routine. Even today, when bidders account for the majority of revenue, if you’re running a lot of banner traffic with Google Ad Manager (GAM) partners, you can still find yourself juggling IDs and instances in your mediation stack. And of course, mistakes happen. A single wrong digit or letter and suddenly the instance ID isn’t valid.
The real shock comes when you catch the error, only to discover that the “broken” instance somehow generated hundreds of thousands of impressions. Neither the mediation platform nor GAM had a clear explanation. To push things further, we deliberately tested what would happen if we entered a completely fabricated GAM placement ID (and confirmed with GAM that it didn’t exist in their system). Incredibly, mediation still reported impressions. That meant the opportunity wasn’t being allocated to a network that could actually serve the ad, leaving us with a direct opportunity cost.
Even now, neither the mediator nor GAM has been able to shed light on this mystery.
So, what’s your take on these experiments? Did any of them catch you off guard? Have you run into oddities like these in your own games? If you’ve got mediation or network test results that left you scratching your head, we’d love to hear them.
This article was originally published as part of the GameBiz Consulting Ad Monetization newsletter #4. Click here to read it.
You might also like











Home of the Gamesforum events series, Mobilize & Monetize podcast, leading mobile game analysis and more about the world of mobile games marketing and monetization.